Model Configuration
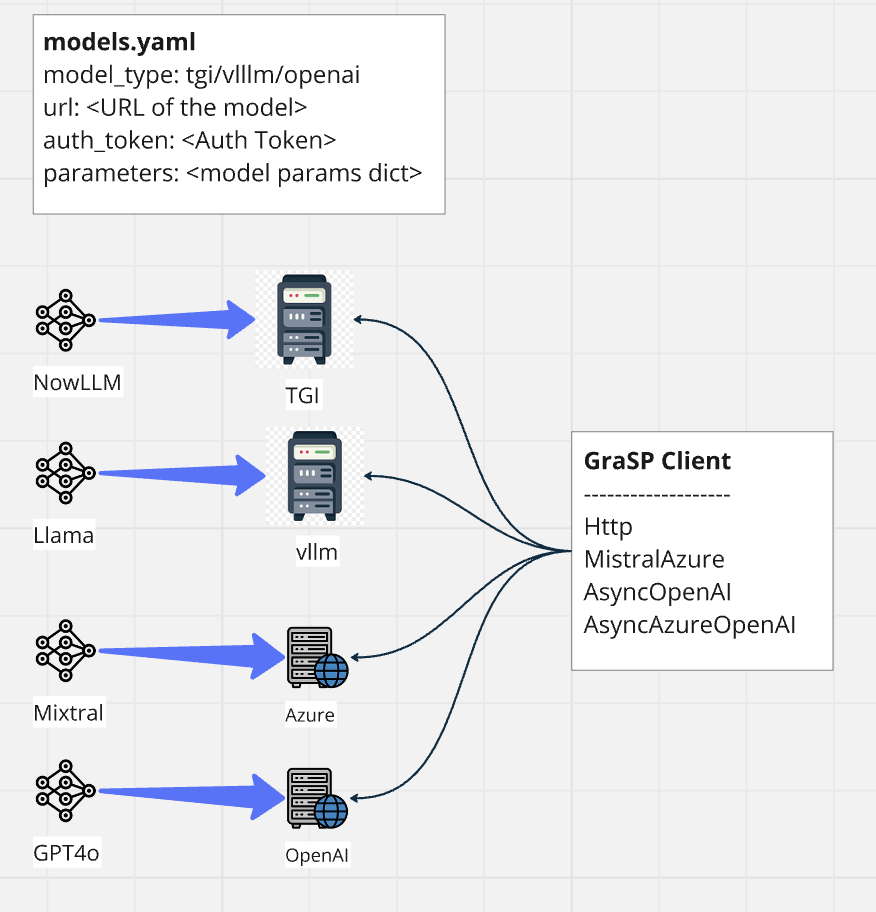
GraSP requires model configuration as the first step. It supports various clients like HTTP, MistralAzure, AsyncOpenAI, AsyncAzureOpenAI, Ollama to connect to inference servers (Text Generation Inference (TGI), vLLM server, Azure Cloud Service, Ollama, Triton etc.).
The config folder contains the main configuration file: models.yaml. You can add your model alias as a key and define its properties as shown below.
Note:
For Triton, the pre-processing and post-processing configuration (payload_json&response_key) can be defined in thepayload_cfg.jsonfile.payload_keyin thepayload_cfg.jsonfile should be added to themodels.yamlfile for the corresponding Triton model. If the payload key is not defined inmodels.yaml, the default payload format will be used.
Environment Variables for Credentials and Chat Templates¶
All sensitive connection information such as model URL and tokens must be set via environment variables and not stored in the config file.
For each model defined in your models.yaml, set environment variables as follows:
- GRASP_<MODEL_NAME>_URL (for the model endpoint)
- GRASP_<MODEL_NAME>_TOKEN (for API keys or tokens)
- If modify_tokenizer: true is set for a model, provide a chat template string via:
- GRASP_<MODEL_NAME>_CHAT_TEMPLATE
Naming Convention:
<MODEL_NAME> is the model’s key from your models.yaml, with all spaces replaced by underscores, and all letters uppercased (e.g., mixtral 8x7b → MIXTRAL_8X7B).
Example:
For mixtral_8x7b and gpt4, set:
- GRASP_MIXTRAL_8X7B_URL, GRASP_MIXTRAL_8X7B_TOKEN
- GRASP_GPT4_URL, GRASP_GPT4_TOKEN
- If mixtral_8x7b has modify_tokenizer: true, set:
- GRASP_MIXTRAL_8X7B_CHAT_TEMPLATE to your custom Jinja2 chat template string
You should use a .env file at the project root or set these in your shell environment.
Note:
If you want to define a list of URLs for any model, you can use pipe (|) as a separator. For example, if you have a model called mixtral_8x7b with URLs https://myserver/models/mixtral-8x7b and https://myserver/models/mixtral-8x7b-2, you can set the following environment variables as shown in examples below.
Example .env:¶
GRASP_MIXTRAL_8X7B_URL=https://myserver/models/mixtral-8x7b|https://myserver/models/mixtral-8x7b-2
GRASP_MIXTRAL_8X7B_TOKEN=sk-abc123
GRASP_MIXTRAL_8X7B_CHAT_TEMPLATE={% for m in messages %} ... {% endfor %}
Configuration Properties¶
| Key | Description |
|---|---|
model_type |
Type of backend server (tgi, vllm, azure_openai, azure, mistralai, ollama, triton) |
model_name |
Model name for your deployments (for Azure/Azure OpenAI) |
api_version |
API version for Azure or Azure OpenAI |
hf_chat_template_model_id |
Hugging Face model ID |
completions_api |
(Optional) Boolean: use completions API instead of chat completions API (default: false) |
modify_tokenizer |
(Optional) Boolean: apply custom chat template and modify the base model tokenizer (default: false) |
special_tokens |
(Optional) List of special stop tokens used in generation |
post_process |
(Optional) Post processor after model inference (e.g. models.model_postprocessor.RemoveThinkData) |
parameters |
(Optional) Generation parameters (see below) |
ssl_verify |
(Optional) Verify SSL certificate (default: true) |
ssl_cert |
(Optional) Path to SSL certificate file |
| > Note: | |
> - Do not include url, auth_token, or api_key in your YAML config. These are sourced from environment variables as described above. |
|
> - If you want to set ssl_verify to false globally, you can set ssl_verify:false under model_config section in config/configuration.yaml |
|
| #### Customizable Model Parameters |
temperature: Sampling randomness (0.0–2.0; lower is more deterministic)top_p: Nucleus sampling (0.0–1.0)max_tokens/max_new_tokens: Maximum number of tokens to generatestop: List of stop strings to end generationrepetition_penalty: Penalizes repeated tokens (1.0 = no penalty)presence_penalty: (OpenAI only) Encourages novel tokensfrequency_penalty: (OpenAI only) Penalizes frequently occurring tokens
The model alias set as a key in the configuration is referenced in your graph YAML files (for node types such as llm or multi_llm). You can override these model parameters in the graph YAML for specific scenarios.
Example Configuration (models.yaml)¶
mixtral_8x7b:
model_type: vllm
hf_chat_template_model_id: meta-llama/Llama-2-7b-chat-hf
modify_tokenizer: true
parameters:
temperature: 0.7
top_p: 0.9
max_new_tokens: 2048
gpt4:
model_type: azure
model_name: gpt-4-32k
api_version: 2024-05-01-preview
parameters:
max_tokens: 500
temperature: 1.0
qwen_2.5_32b_vl:
model_type: vllm
completions_api: true
hf_chat_template_model_id: Qwen/Qwen2.5-VL-32B-Instruct
parameters:
temperature: 0.15
max_tokens: 10000
stop: ["<|endoftext|>", "<|im_end|>", "<|eod_id|>"]
qwen3_1.7b:
hf_chat_template_model_id: Qwen/Qwen3-1.7B
post_process: grasp.core.models.model_postprocessor.RemoveThinkData
model_type: ollama
parameters:
max_tokens: 2048
temperature: 0.8
qwen3-32b-triton:
hf_chat_template_model_id: Qwen/Qwen3-32B
post_process: grasp.core.models.model_postprocessor.RemoveThinkData
model_type: triton
payload_key: default
# Uses default payload format defined in config/payload_cfg.json.
# Add/Update the payload_cfg.json if you need to use a different payload format with new key.
parameters:
temperature: 0.7
Important: If you set modify_tokenizer: true for a model, you must provide the corresponding chat template in your environment as GRASP_
_CHAT_TEMPLATE. Otherwise, exception will be raised during the model initialization.