
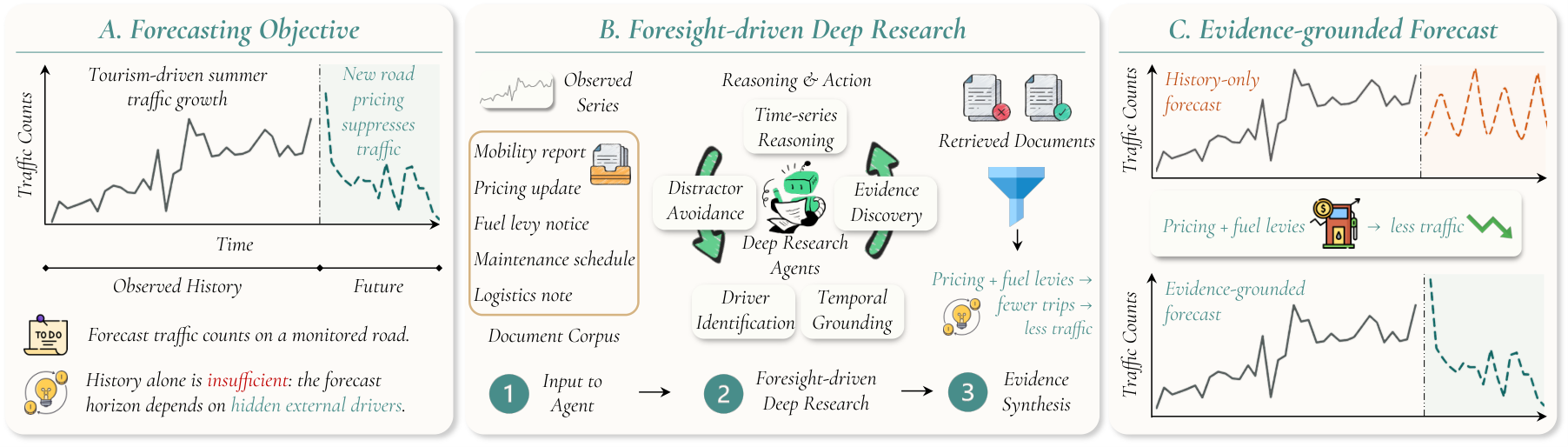
Forecasting needs context you have to go find
Time-series forecasting in the real world rarely depends on history alone. A traffic forecast hinges on a planned road closure; a demand forecast hinges on an upcoming promotion; a sensor forecast hinges on a maintenance window. That context lives in documents — reports, tickets, notes — scattered across noisy, heterogeneous sources, mixed in with material that looks relevant but is not.
Existing context-aided forecasting benchmarks hand the model the right context up front. That leaves the central question untouched: can an agent identify the right context on its own? Dr-CiK is built to answer it.
Context is Key
When it comes to forecasting, the right external context often matters more than a better model. Quality context substantially improves forecasts.
Deep Research
Finding that context in a large corpus — and distilling it into forecast-useful evidence while rejecting distractors — demands genuine deep research.
What an agent has to do
Each task pairs a time series with a corpus of supporting and distractor documents, and the agent works through four steps to produce an evidence-grounded forecast.
Retrieve
Search the document space for context relevant to the series being forecast.
Filter
Reject distractors — confounders, noise, profile and temporal mismatches, and misleading time-series claims.
Distill
Turn the retrieved context into concise, forecast-useful evidence.
Forecast
Produce a forecast grounded in that evidence — and be judged against ground truth.
Of the 10,342 documents, 3,367 are supporting and 6,975 are distractors — exactly five per distractor type per task. Tasks span synthetic and human-authored sources across domains like infrastructure, healthcare, transportation, and systems observability. Ground-truth evidence and future values are retained for evaluation.
Today's agents struggle to find the future's context
Context pays off. With ground-truth context, the best forecaster cuts scaled CRPS by roughly 40% versus no context — the prize is real.
But evidence is missed. Most deep-research agents recover under 5% of the ground-truth supporting evidence in a task.
And distractors win. Agents are frequently misled — a large majority of cited documents are distractors, and retrieved context can push forecasts below the no-context baseline.
Results
Two leaderboards — forecasting and deep-research quality. The official ranking is on the hidden test set (80 tasks, labels withheld, scored by us); the paper's 240-task results are kept as reference. Switch protocol and sort any column.
Look inside a task
Each task is a time series, a forecast target, ground-truth evidence, and a corpus of supporting and distractor documents. Explore a few interactively.
A scheduled load spike
Predict server CPU where an upcoming batch job, buried in ops notes, reshapes the trajectory the history alone can't reveal.
View full task →Cloud cover over a solar site
Forecast global horizontal irradiance where the swing is explained by an incoming weather pattern described in the corpus — amid look-alike distractors.
View full task →A promotion that moves demand
Predict daily sales when an upcoming promotion and calendar effects — stated in supporting documents — bend the trend away from history.
View full task →Cite Dr-CiK
@article{tang2026dr,
title={Dr-CiK: A Testbed for Foresight-Driven Agents},
author={Tang, Yihong and Williams, Andrew Robert and Ashok, Arjun and Zheng, Vincent Zhihao and Sun, Lijun and Drouin, Alexandre and Laradji, Issam H and Marcotte, {\'E}tienne and Zantedeschi, Valentina},
journal={arXiv preprint arXiv:2605.27904},
year={2026}
}